
Анализ городской среды через гео-данные фотографий из VK
Однажды захотелось поработать с VK API и картографическими сервисами Google. За основу взял задачу определения мест в городах Крыма пользующихся наибольшей популярностью и пользователей соцсети, т.е. требовалось собрать все фотографии сделанные в заданной области (VK хранит информацию о том, где была сделана фотография) и сформировать из этого набора тепловую карту.
В данной статье покажу полученные результаты, программу для повторения моих опытов и опишу ограничения с которыми пришлось столкнуться. Для работы с данными и интерфейсами VK и Google использовал язык Python и Jupyter Notebooks.
Для анализа взял несколько мест на карте - города пользующиеся популярностью у туристов - Евпатория, Севастополь, Ялта; и Симферополь, как представитель крупного города, где гости не задерживаются надолго и как таковые туристические объекты отсутствуют.
Используемые инструменты
- Python 3.7
- JupyterLab 0.35.4
- Библиотеки python:
Не буду расписывать настройку среды и все подготовительные действия, они есть на официальных сайтах инструментов. Все довольно просто. Но упомяну, что библиотека jupyter-gmaps требует пересборки jupyter (см. инструкции по установке).
Программа для сбора и обработки данных
Для начала подключим и импортируем библиотеки:
import pandas as pd
import gmaps
import gmaps.datasets
import requests
from random import randint
from datetime import datetime
from time import sleep, strftime, localtime, mktime, strptime
from csv import DictWriter, DictReader
Потом необходимо создать свое приложение VK пользуясь этим руководством. И приложение Google по этой инструкции. В итоге мы получим два токена (где ‘…’ это различные символы) или ключа для работы с API сервисов.
GOOGLE_API_KEY = 'AI......'
VK_ACCESS_TOKEN = 'd05......'
VK_VERSION = '5.92'
Затем требуется так называемая инициализация переменных
geo = (44.498231, 34.169317) # точка поиска - Ялта администрация (взял из карт)
dist = 3000 # радиус поиска фотографий (в метрах)
timeperiod = (1514764800, 1546300800) # диапазон времени в котором сделано фото
# ( 00:00 1.01.2018, 00:00 1.01.2019 )
Описание функции для получения данных от VK. На выходе получаем JSON структуру.
def getVK(geo, timeperiod, offset):
params = {
'lat': geo[0],
'long': geo[1],
'count': '1000',
'offset': offset,
'radius': dist,
'start_time': timeperiod[0],
'end_time': timeperiod[1],
'access_token': VK_ACCESS_TOKEN,
'v': VK_VERSION,
'sort': 0 # by date of creation
}
return requests.get("https://api.vk.com/method/photos.search",
params=params, verify=True).json()
Получаемый ответ будем сохранять в структуру map (словарь), где ключом будет пара - id фото и время фото.
Это позволит избежать повторов одинаковых фотографий.
Производить сохранение в словарь будем через функцию, принимающую на входе ответ сервера и сам словарь.
Там же сделаем обработку исключений, т.к. иногда ответ выдает пустой JSON.
В переменную map_data сохраняем непосредственно GPS координаты фотографии.
def save_to_map(resp, map_data):
try:
items = resp['response']['items']
except KeyError:
return
for f in items:
try:
map_data[(f['id'], f['date'])] = (f['lat'], f['long'])
except KeyError:
continue
И пожалуй самое главное - функция для запуска сбора данных из VK.
Что в ней важно?
Используется метод photos.search.
Поиск фото ведется циклически в течение заданного временного промежутка с шагов в 24 часа (сутки) - сделано для того, чтобы преодолеть ограничение VK на максимальное количество возвращаемых фото (3000 фото) при одинаковом запросе.
Сделан цикл для получения дополнительных фотографий, которые не были получены в первый раз (расчет сдвига - offset). И если обработка зацикливания в случае преодоления этого лимита. В общем, есть одна особенность - мы не можем получить больше 3000 фотографий за сутки, все остальные будут так или иначе отброшены. Но в данном примере ими можно принебречь. Т.к. данных для анализа все равно будет достаточно. И да, пришлось добавить вызов функции sleep(0.5) для того чтобы не слать очень часто запросы и VK не забанил бы приложение.
map_data = {}
step = 24*60*60 # шаг - день
i = timeperiod[0]
while i < timeperiod[1]:
resp = getVK(geo, i, i+step, 0)
save_to_map(resp, map_data)
count = resp['response']['count']
returned = len(resp['response']['items'])
if count > returned:
offset = returned
while offset < count and offset < 3000:
resp = getVK(geo, i, i+step, offset)
save_to_map(resp, map_data)
count = resp['response']['count']
returned = len(resp['response']['items'])
offset = offset + returned
if returned == 0:
break
i = i + step
sleep(0.5)
Дальше написал функции для сохранения полученного словаря map_data с данными о расположении фотографий и чтении этих данных обратно в словарь. Это чтобы не производить сбор данных еще раз и в будущем был бы уже готовый датасет.
def save_map_to_csv(map_data, path):
with open(path, 'w', newline='', encoding='utf-8') as csvfile:
columns = ['id', 'date', 'lat', 'long']
writer = DictWriter(csvfile, fieldnames=columns, delimiter=';')
writer.writeheader()
for key in map_data:
data = {
'id': key[0],
'date': strftime("%d.%m.%Y", localtime(key[1])),
'lat': map_data[key][0],
'long': map_data[key][1],
}
writer.writerow(data)
def read_csv_to_map(map_data, path):
with open(path, newline='', encoding='utf-8') as csvfile:
reader = DictReader(csvfile, delimiter=';')
for row in reader:
map_data[(int(row['id']),
int(mktime(strptime(row['date'], '%d.%m.%Y'))))] =
(float(row['lat']), float(row['long']))
Воспользуемся сохранением в CSV формат полученных данных
save_map_to_csv(map_data, 'yalta2018.csv')
И последнее, что осталось сделать это нанести фотографии на карту и создать из них тепловую карту, для выявления очагов, где было сделано наибольшее количество фотографий.
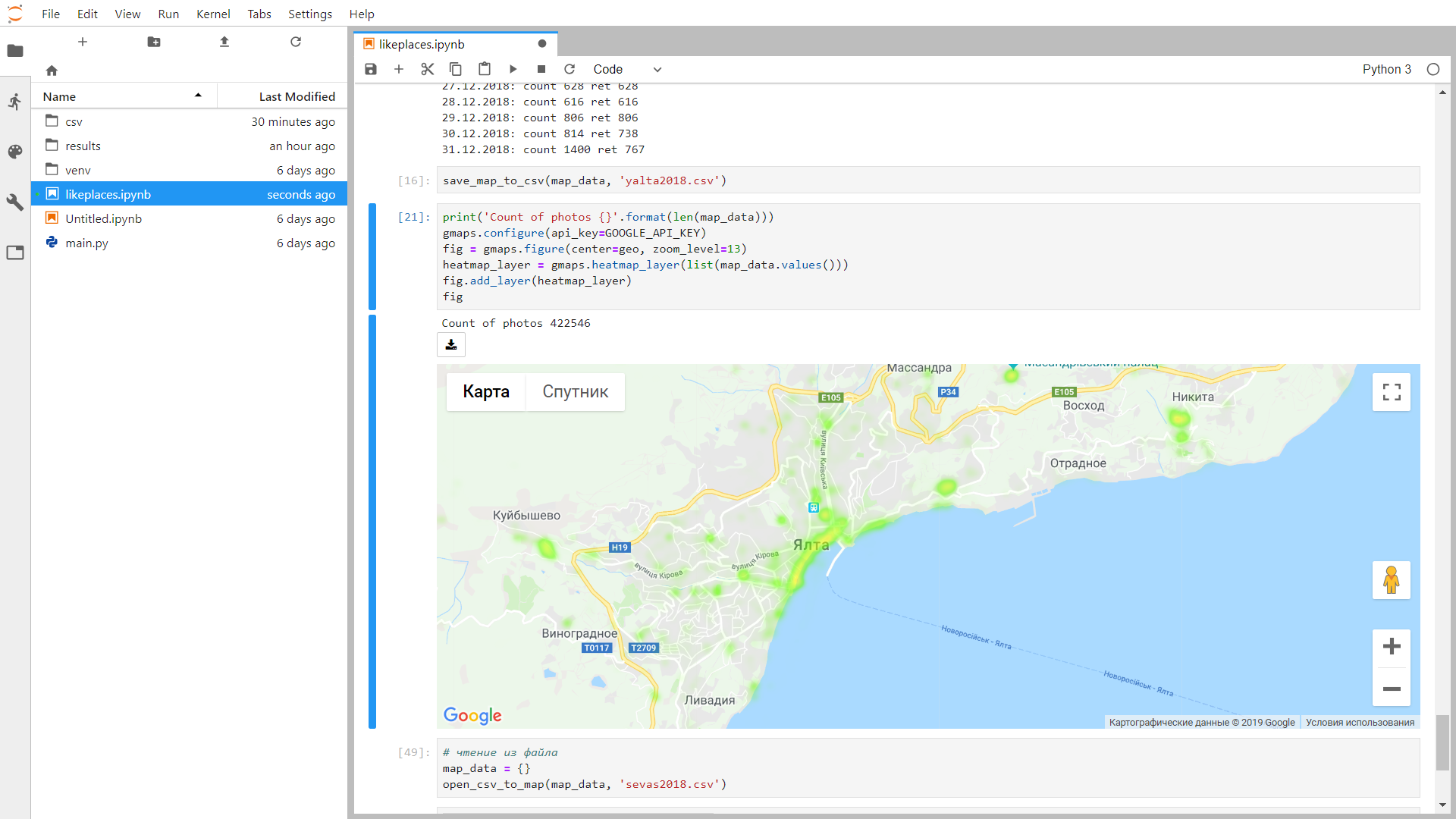
print('Count of photos {}'.format(len(map_data)))
gmaps.configure(api_key=GOOGLE_API_KEY)
fig = gmaps.figure(center=geo, zoom_level=13)
heatmap_layer = gmaps.heatmap_layer(list(map_data.values()))
fig.add_layer(heatmap_layer)
fig
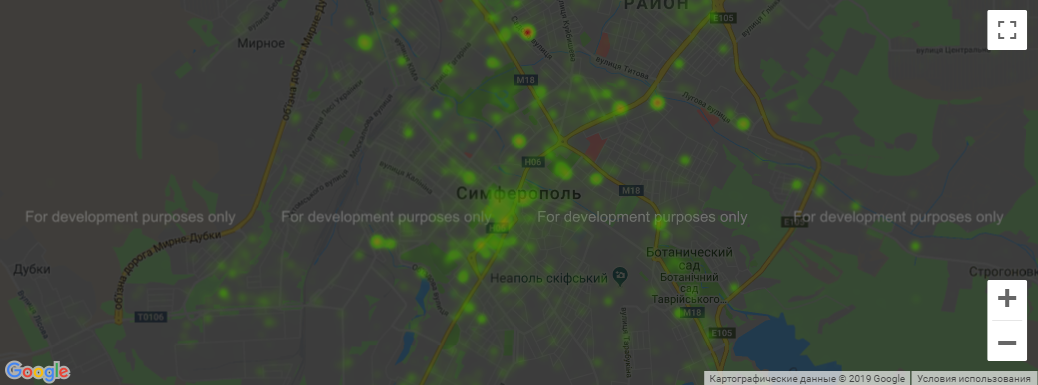
У Google тоже есть ограничение на максимальное количество запросов в день и др. Тогда карта окрашивается в темный цвет (см. пример с Симферополем). В таких случаях я просто создал еще одно приложение и получил новый токен.
В общем, вот так выглядит программа и полученная тепловая карта в JupyterLab
Результаты
В итоге были получены следующие результаты. Я их скомпоновал и выложил в открытый доступ.
Евпатория - 2017 год
Собрано около 217 тысяч фотографий - итоговый CSV-файл.
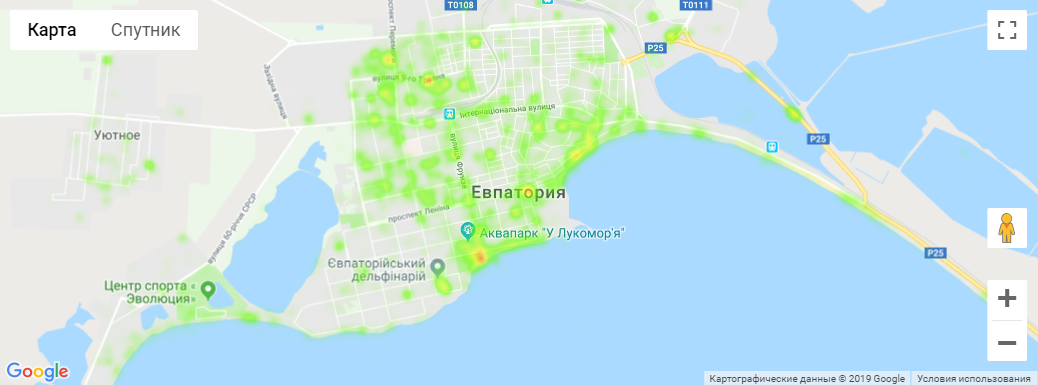
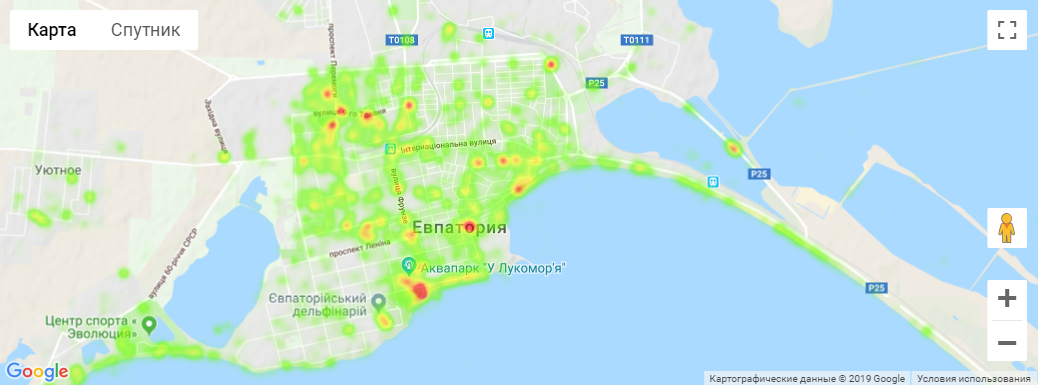
Евпатория - 2018 год
Собрано около 273 тысяч фотографий - итоговый CSV-файл.
Симферополь - 2017 год
Собрано около 370 тысяч фотографий - итоговый CSV-файл.
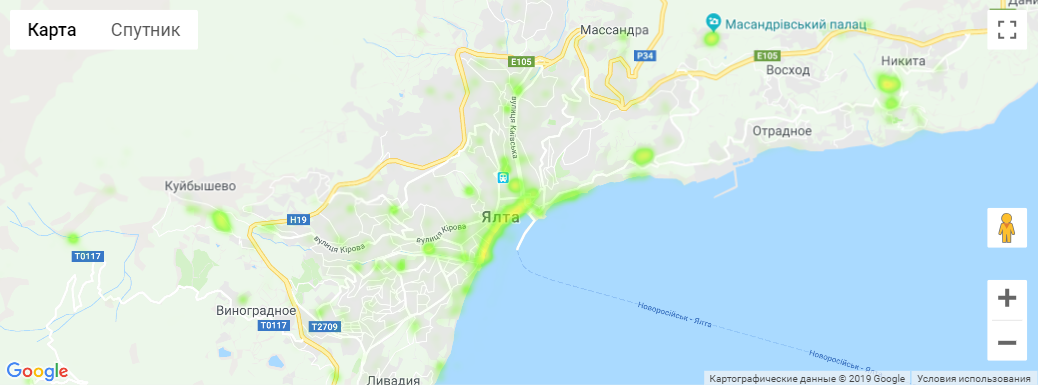
Ялта - 2018 год
Собрано около 422 тысяч фотографий - итоговый CSV-файл.
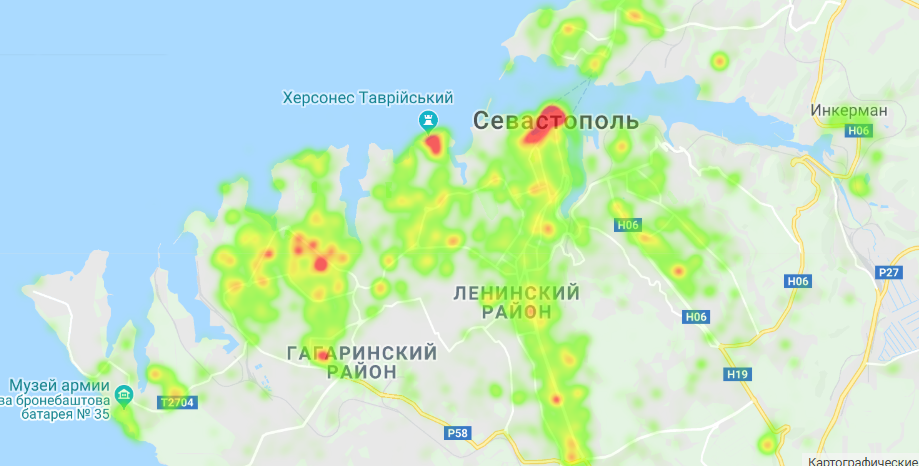
Севастополь - 2018 год
Собрано около 1 232 тысяч фотографий - итоговый CSV-файл.
Выводы
Помимо полученного опыта работы с API google и VK, удалось с помощью соцсетей вычислить места более всего принятые для фотографирования. Это может быть началом для более глубокой аналитики. Например, где сегментации по полу, возрасту, городу; определение временных предпочтений (что популярно днем/ночью, летом/зимой) и пр. А для себя, благодаря исследованию, я нашел пару примечательных мест недалеко от Евпатории, которые собираюсь в ближайшее время посетить.



