Monitoring system for Docker SLURM cluster
Institute of Continuous Media Mechanics (ICMM UB RAS) has a high-performance cluster consist of about 50 nodes with >400 CPUs and more than 1 TB RAM. It’s needed to make models of new materials and calculate its properties. And in the future, the Institute has plans to upgrade his infrastructure and virtualize his resources to get less dependencies of a hardware layer. The cluster uses Slurm workload manager to run programs on compute nodes. With SLURM many scientist can easy run his programs on the cluster in parallel and independent.
And I should work with these systems. My primary task is to make scripts for deploying virtual compute infrastructure with Docker. My second task is to design and configure a monitoring system to collect and view system statics in the real-time.
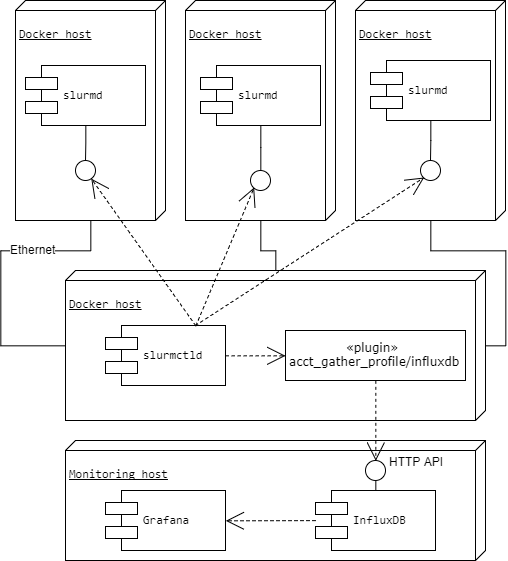
Has been developed a script that deploying a simple SLURM configuration with docker-compose. Instead of docker-compose could be used docker stack command with Docker Swarm to deploy containers to a compute nodes with included SLURM software. All information is described on GitHub.
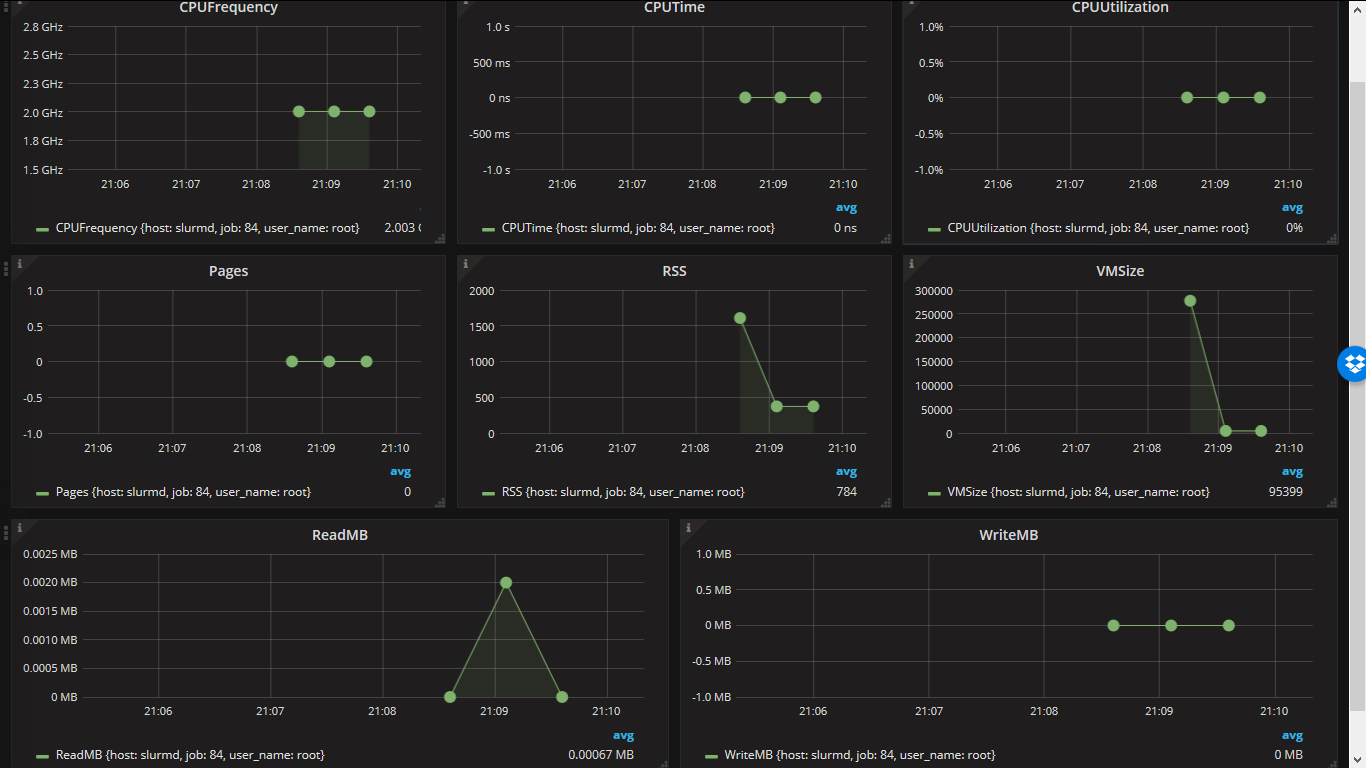
I have used a stack InfluxDB+Grafana, I’ve known good from my previous work, to realize a monitoring system. I use HDF5 profiling plugin for collecting data about runned tasks. This plugin was based of work of the cfenoy user. I’ve modified it to work with the last SLURM version and add gathering some new fields. Also was configured a Grafana dashboard that helps view all statistics about task that have been ever run on the HPC cluster.
docker-slurmbase:
https://github.com/GRomR1/docker-slurmbase
influxdb-slurm-monitoring:
https://github.com/GRomR1/influxdb-slurm-monitoring