Система мониторинга вычислительного кластера на Docker и SLURM
Институт механики сплошных сред УрО РАН имеет вычислительный кластер на базе суперкомпьютера состоящего из около 50 узлов с >400 CPU и >1 ТБ оперативной памяти. Он используется в научной работе различными подразделениями института для построения математических моделей и расчета различных параметров.
В будущем Институт планирует обновить свою инфраструктуру и виртуализировать свои вычислительные ресурсы для снижения зависимостей физического уровня аппаратуры. В кластере используется менеджер задач SLURM для запуска программ на вычислительных узлах. Благодаря нему многие сотрудники Института могут запускать одновременно и независимо друг от друга свои задачи.
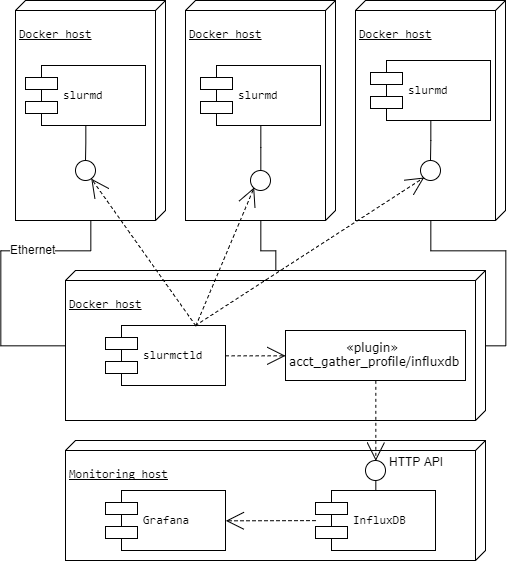
И я должен был разобраться с этой системой. Моей основной задачей было написание скриптов для развертывания виртуальной вычислительной инфраструктуры на базе Docker Docker. Затем мне требовалось разработать и сконфигурировать системы мониторинга системной статистики в реальном времени.
Для развертывания виртуального кластера был написан скрипт для docker-compose. Его подробности выложены на GitHub.
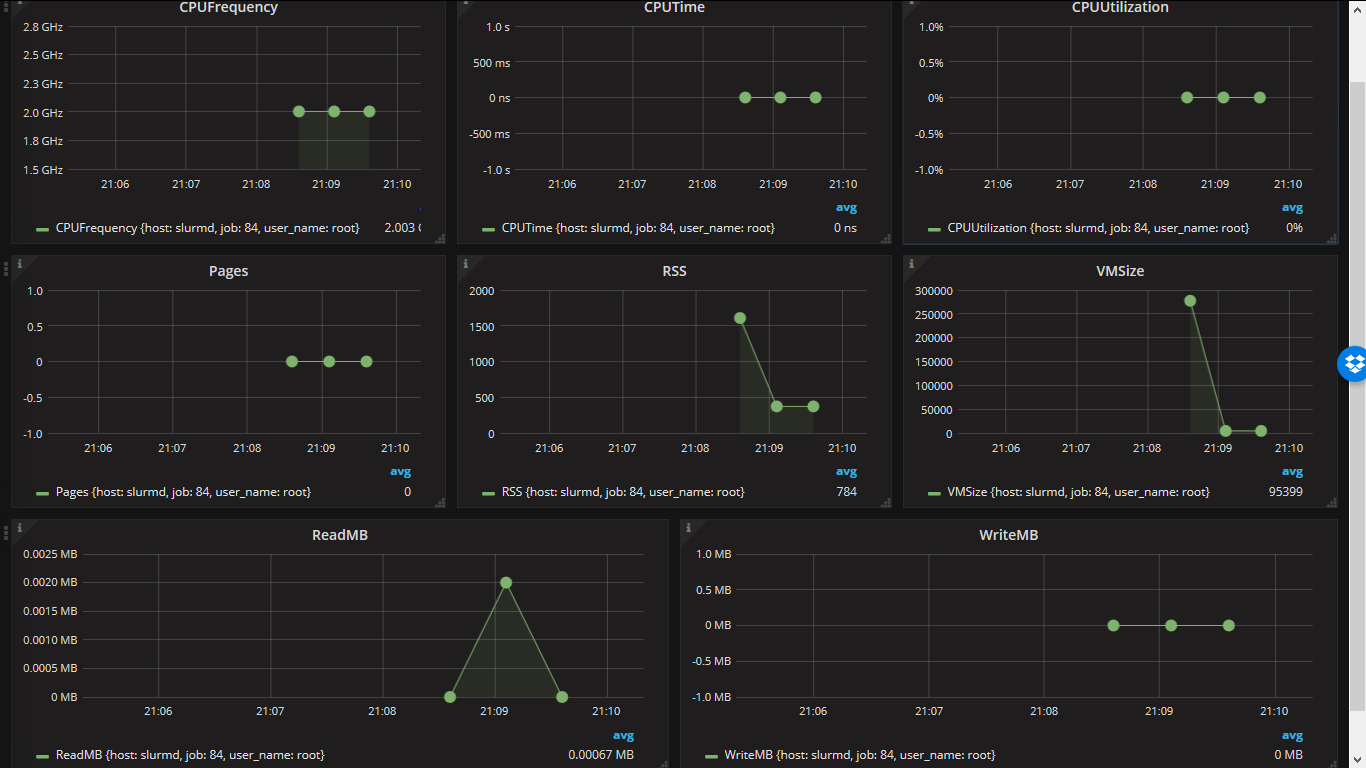
Для мониторинга я использовал стек InfluxDB+Grafana, Я его хорошо знаю по своей предыдущей работе. Сбор данных о запущенных задачах происходил с использованием плагина-профилировщика HDF5. Этот плагин был основан на работе пользователя cfenoy. Я его модифицировал для работы с последней версией SLURM и добавил сбор нескольких дополнительных полей. Также был создан и настроен дашбоард в системе Grafanf, который помогает наблюдать всю статистику кластера в браузере в реальном-времени.
docker-slurmbase:
https://github.com/GRomR1/docker-slurmbase
influxdb-slurm-monitoring:
https://github.com/GRomR1/influxdb-slurm-monitoring